


ES 分数不唯一的问题
每个 index 通常会分布在多个 shards ,例如默认配置是 5,相同原文在同一 query 下分数有偏差的主要原因是不同 shards 中 term 出现频率不一致(TF )。
几种缓解的办法:
- 足够多的 doc 可以拉平不同 shards 的差异
- 减少所用 index 的 shards 数量,和上面方法类似
?search_type=dfs_query_then_fetch(DFS Distributed Frequency Search) 集合所有 shards 的 TF 最后计算分数,等同于 number_of_shards = 1
BM25
BM25 score 的基本方程:
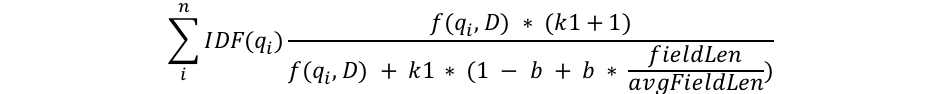
IDF: 罕见的词区分度更高,分数加成更高
fieldLen/avgFieldLen: 文本越长,总分数越低
b: es 中默认是 0.75,越小,对于上述的当前文本长度与平均文本长度的比值对分数的影响越小,b 为 0 时,分数只与 count 和 relevance 呈正相关
f(qi,D): tf,文档D 中 query i 出现的频率,频率越高,分数越高
k1: es 中默认是 1.2 ,控制 tf 的斜率,随着 term 出现次数逐渐降低对分数提升的影响,即Term frequency saturation(词频饱和度),当 k1 是 0 时,等于只计算 IDF。
下图是传统 TF 与 BM25 TF 的分数变化曲线对比:
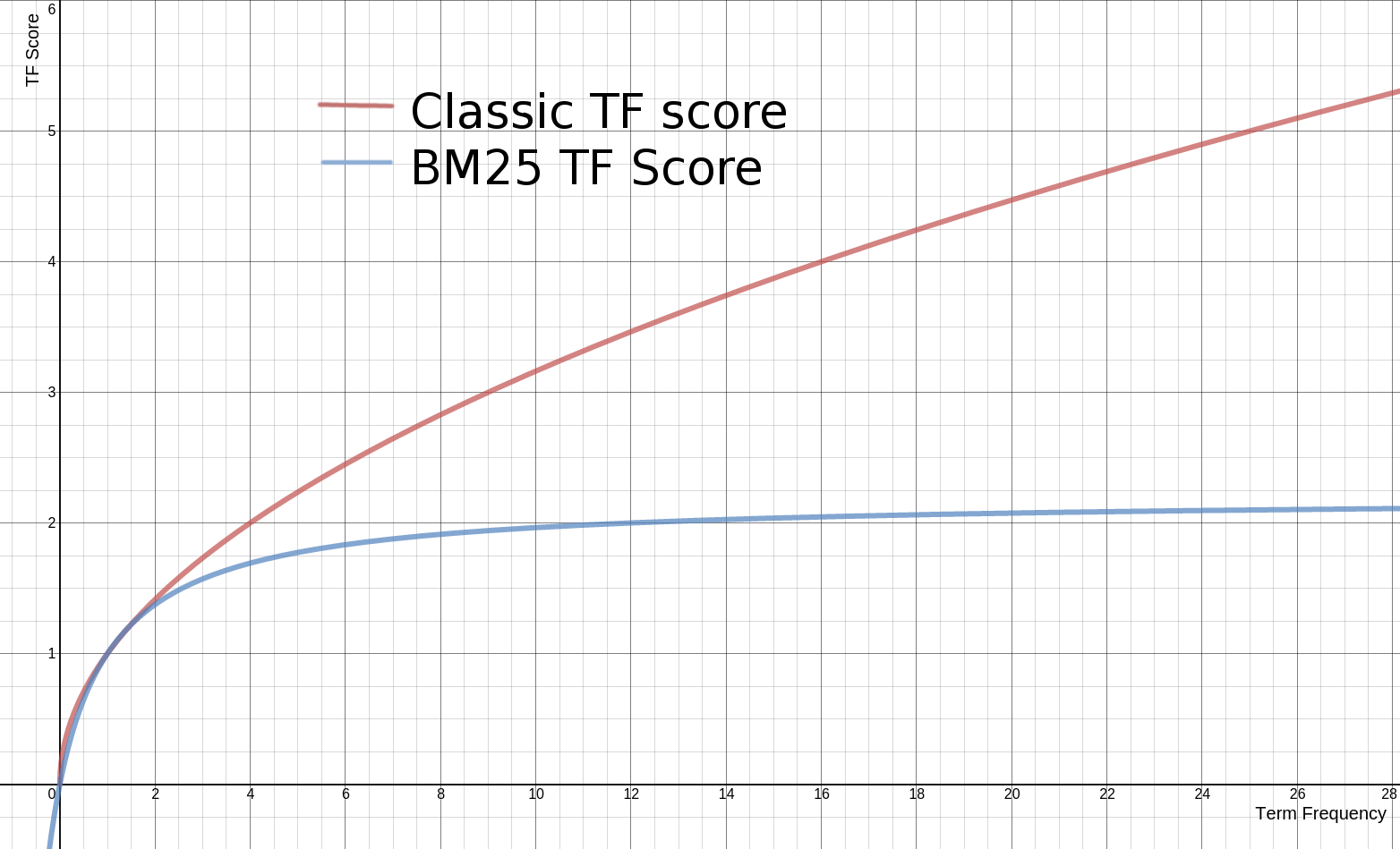
传统 tf/idf 的 tf 会无限提升分数,BM25 则在 tf 达到饱和后一定程度缩小了对相关性的影响。
变量的使用
原则上不建议调整 b 和 k1 的默认值,优先考虑下列方法:
- 最常用的 boost score on query field
- 近义词匹配
- 在 index 和 query 阶段分别通过 analyzer 提前处理
- 考虑几种 function score Function score query | Elasticsearch Reference 7.6 | Elastic
与小说、长文献不同,考虑 resume content 的场景,对于频繁出现技能和结果的词汇,可以适当降低 k 值,因为简历文档足够精简,信息确切,出现的 term 基本代表着一个人的信息,这时我们希望 term 迅速饱和;于此同时针对稍长的混杂着除职责本身的公司福利、发展状况、服务客户等 职位JD 场景,我们可以适当提高 b 值,把冗长的与用户搜索无关信息过滤掉。
参考
BM25 paper
BM25F paper
Index-modules-similarity
Improved Text Scoring with BM25 | Elastic
Okapi BM25 - Wikipedia
Practical BM25 - Part 1: How Shards Affect Relevance Scoring in Elasticsearch | Elastic Blog
Practical BM25 - Part 2: The BM25 Algorithm and its Variables | Elastic Blog
Practical BM25 - Part 3: Considerations for Picking b and k1 in Elasticsearch | Elastic Blog
Quantitative Cluster Sizing | Elastic
BM25 The Next Generation of Lucene Relevance